

728x90
반응형
인덱스 란?
- 원하는 데이터를 쉽게 찾을수 있도록 돕는 자료구조이다.
- 검색 조건에 부합하는 데이터를 효과적으로 빠르게 검색 할 수 있도록 돕는다.
- 하지만 인덱스 효율이 나쁘면 오히려 느릴 수 있다.
- 1개의 테이블에 인덱스가 많은면 CUD 작업시 부하가 발생 할 수 있다.
- 이유는 저장 하거나 업데이트 할때 인덱스 값을 조정 해줘야 하기 때문이다.
인덱스의 자료구조
Hash
- 해시는 탐색 시간이 빠르지만 자료를 저장 할때 정렬이 되지 않는다.
당연한것이 해쉬 자료구조 이기 때문이다.
DB 에서는 특정 범위를 검색하는 경우가 있는데 이에 적절하지 않아서 잘 사용하지 않는다.
B * Tree
- DB 에서 가장 많이 사용하는 인덱스 구조이다.
B * Tree 인덱스 란?
- DBMS 에서 사용되는 가장 일반적인 인덱스이다.
B * Tree 구조
- 루트블록
- 가장 상위에 존재하는 블록 - 브랜치 블록
- 분기 목적의 블록 - 리프 블록
- 트리의 가장 아래 단계에 존재하는 블록
다음예제는 직원 테이블에 직원명으로 인덱스가 걸려 있을때
동작하는 방식이다.
SELECT * FROM 직원
WHERE 직원명 = '차두식'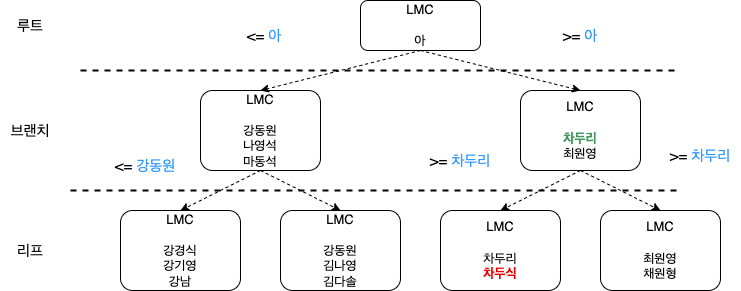
- 각각의 블록 들은 하위 블록에 대한 주소 값을 갖는다.
- LMC 가 가르킨 블록에는 첫번째 레코드 보다 작거나 같은 레코드가 저장
- 리프블록의 각레코드는 정렬 되어 있으며 테이블 레코드를 가리키는 주소값을 가진다.
- 인덱스 키 값이 같으면 ROWID 순으로 정렬된다.
- 인덱스를 스캔하는 이유는 소량의 데이터를 빨리 찾고 ROWID 를 얻기 위함이다.
- ROWID 를 얻어 테이블에 접근 하여 컬럼을 찾아간다.
효율적인 인덱스를 위해
- 카디널리티가 높은 컬럼을 선택하자.
- 카디널리티가 높다는 것은 중복도가 낮다는 것이다.
- 예를 들어 주민번호 같은경우는 중복도가 없다 -> 카디널리티가 높다.
랜덤 액세스 최소화
- 인덱스 스캔을 최소화 하자
인덱스 스캔후 추가 정보를 가져오기 위해 리프 블록에 있는 ROWID를 가지고 테이블에서 해당 행을 찾기 위한
테이블 랜덤 액세스를 수행한다. 테이블 랜덤 액세스는 DBMS 성능 부하의 주 요인이다. - 인덱스 스캔이 비효율 적이라 판단이 되면 풀스캔을 하게 된다.
- 테이블 풀 스캔은 랜덤 액세스가 발생하지 않는다.
풀스캔을 하는 경우
- 조건문이 없는경우
- 사용가능한 인덱스가 없는경우
- 풀스캔이 유리하다고 판단되는 경우
- LIKE 에서 %text% 로 조회 하는 경우
참고:
이경오의 SQL+SQLD
728x90
반응형
'DataBase > DB 기초' 카테고리의 다른 글
| [DB] LIKE 와 INDEX (0) | 2023.02.10 |
|---|---|
| [DB] NoSQL (0) | 2021.08.19 |
| [DB] Index 기초 (0) | 2021.08.19 |
| [DB] GROUP BY (0) | 2021.08.05 |
| [DB] Join (0) | 2021.08.05 |

댓글