

728x90
반응형
ORDER BY, PARTITION BY
먼저 각각의 기능에 대해 알아보자.
Table 생성시 적용가능한 옵션들
- 테이블 생성시 아래와 같은 필수값과 옵션을 줄수 있다.
- 우리는 그중 ORDER BY 와 PARTITION BY 를 보자
- 다른 옵션값에 대란 자세한 사항은: https://vprog1215.tistory.com/392 해당글 참고
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]
ORDER BY
- 클릭하우스는 sorting key 를 기본적으로 PK 로 사용한다.
- ODER BY 를 주게 되면 해당 값을 기준으로 데이터가 정렬 되어 들어 온다.
- 그렇다면 조회 속도에 영향을 줄것이라는 예상이 간다.
PARTION BY
- 파티션 키 데이터를 분리하여 별도의 파일로 만들수 있다.
- 파티션의 기준은 날짜로 봤을때 Month 월 까지가 적당하다.
- 그이유는 오히려 너무 많이 쪼개면 분포도가 넓어지게되어 속도 저하가 발생 할 수 있다.
- 파티션의 경우 큰 속도영향을 미치지 않는다고 써있지만 이것은 무분별하게 사용할 경우 오히려
독이 되기 때문에 초보자들은 안쓰게 좋다는 답변을 받았다.
Granules
- 그렇다면 키를 잘 주었는지 혹은 파티셔닝을 잘 했는지 어떻게 판단할수 있을까?
- 우리는 granules 값으로 파악할수 있다.
- MergeTreeEngine 의 경우 데이터는 파트별로 구성이 되어져 있다.
- 하나의 파트안에는 8192 rows 이 있는데 이것을 granule 이라고 부른다.
즉 더이상 나눌수 없는 최소 단위의 행 수의 집합이라고 생각하면 편 할 것 같다. - granule 은 PK 와 동일한 ODER BY 인덱스에 의해 참조된다 그래서 ORDER BY 값을 잘 정해야 한다.
- 즉 ODER BY 값을 잘 주면 필요없는 granule 을 스킵하여 관계가 있어보이는 값들만 찾아 빠른 속도를 낼 수 있다.
예제
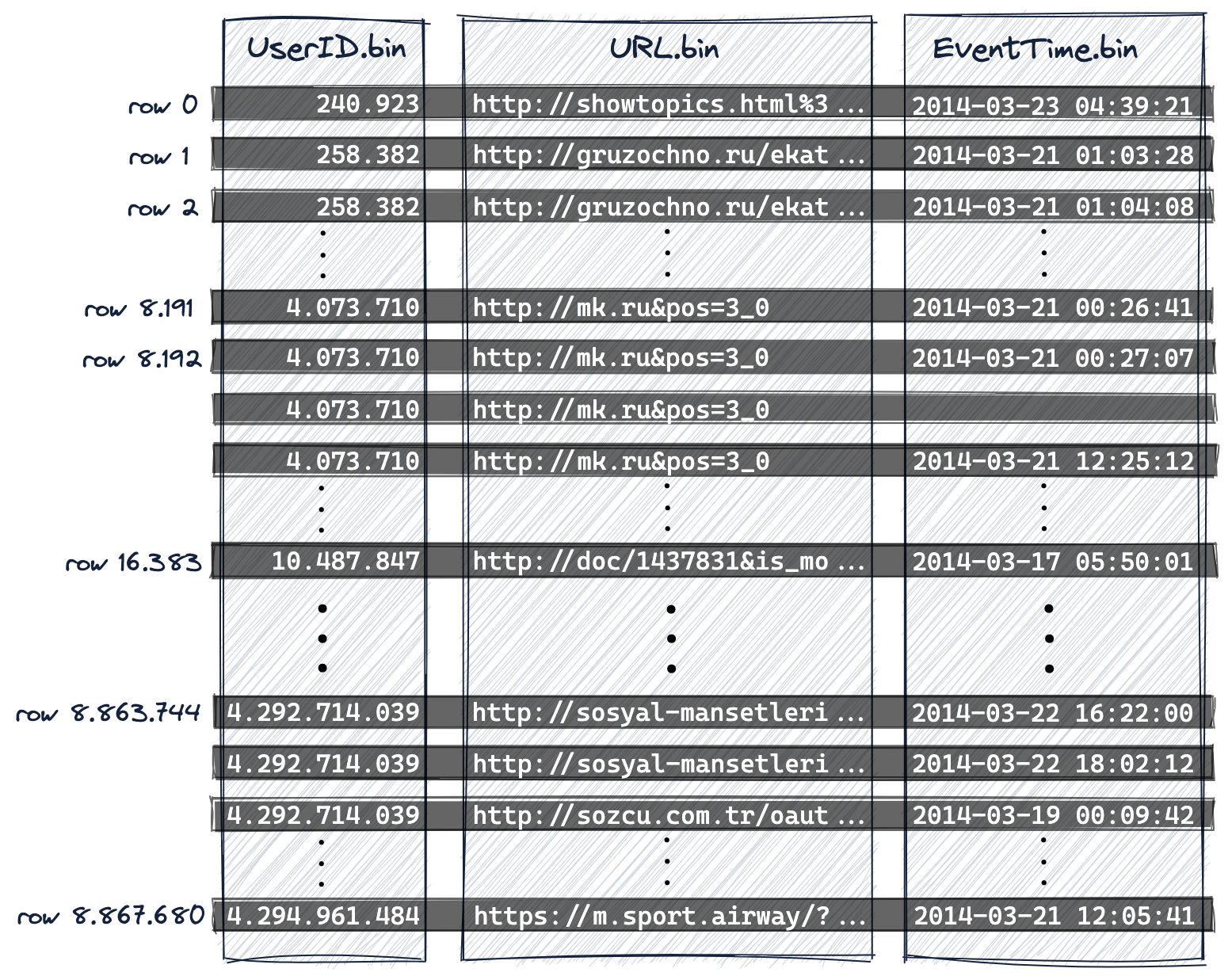
데이터 예제
아래 처럼 데이터가 적재 되어 있다고 가정하다.
ODER BY 는 UserId URL, EventTime 순으로 되어 있다.
granule 선정 되는 방식
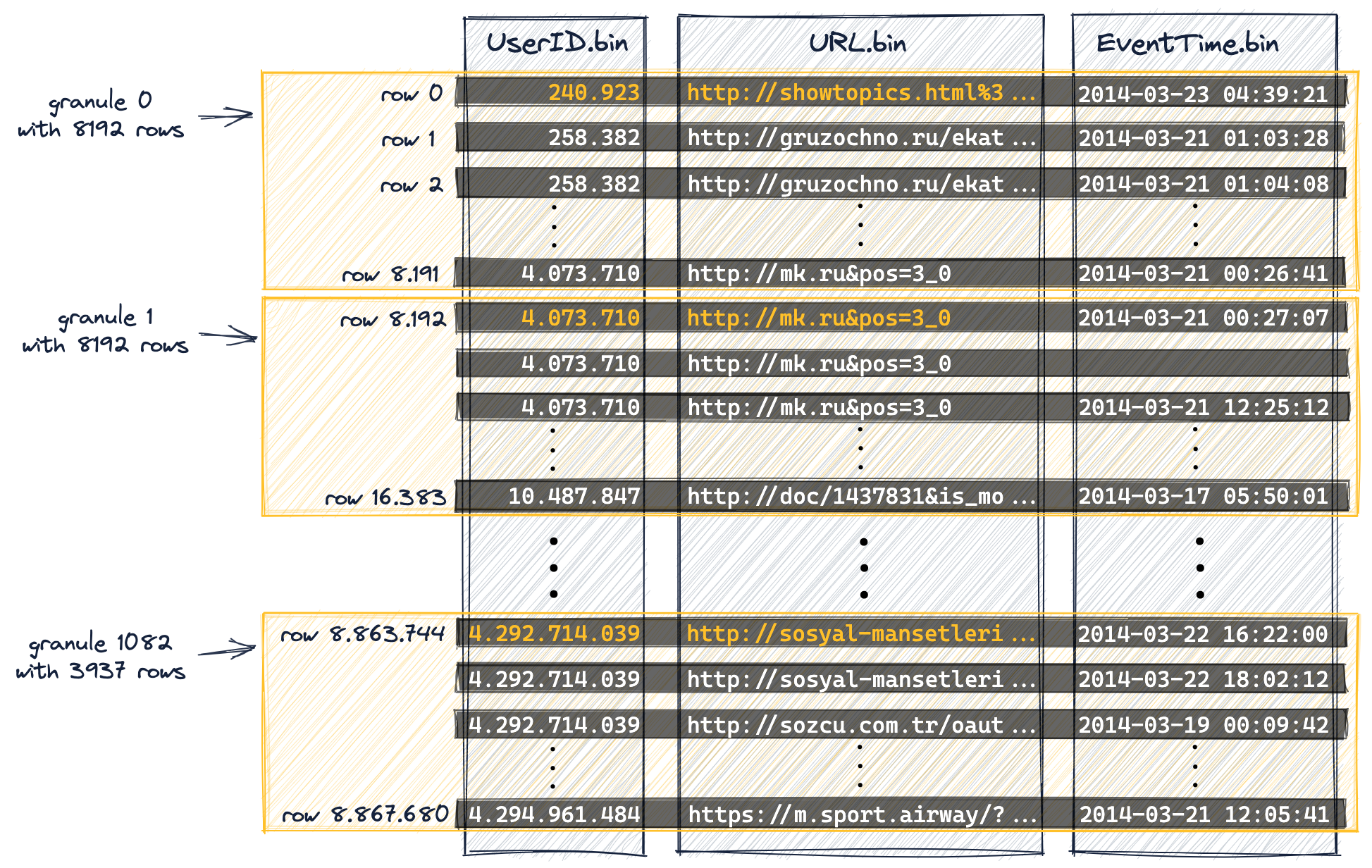
granule 0:위 그림에서 granule 0 은 처음 값 부터 8192 행들을 포함한다.
granule 1: 그다음 값인 8192 행에서부터 8192 행 수만큼 포함을 하게 된다.
granule 1082: granule 순서대로 값을 저장하면서 생긴다
granule 을 가진 데이터 조회
- mark0: granule 0 번째 처음 행
- mark1: granule 1 번째 처음 행
- 자 이제 검색을 할때 마크된 값으로 데이터를 조회 하기 때문에 클릭하우스는 전체를 검색하지 않고
필요한 부분만 검색이 가능하게 된다.

반응형
Granule 값 분석해보기
- explain indexes=1 값으로 몇번 파티션에 접근 했는지 등
정보를 알 수 있다.
explain indexes=1
SELECT * FROM example_table
- 조회하면 아래처럼 나오게 된다.
- 가장 좋은 방법은 앞단에서 데이터가 많이 걸러 져야 한다.
- Initial granule 보다 Selected granule 이 작아야 한다.
"Node Type": "ReadFromMergeTree",
"Indexes": [
{
"Type": "MinMax", -- 시간등 범위값
"Keys": ["y"],
"Condition": "(y in [1, +inf))",
"Parts": 5/4,
"Granules": 12/11 -- - 초기 granule 12, 선택된 granule 11
},
{
"Type": "Partition", -- 데이터를 조회하기 위해 접근한 파티션 수
"Keys": ["y", "bitAnd(z, 3)"],
"Condition": "and((bitAnd(z, 3) not in [1, 1]), and((y in [1, +inf)), (bitAnd(z, 3) not in [1, 1])))",
"Parts": 4/3,
"Granules": 11/10
},
{
"Type": "PrimaryKey", -- PK 로 걸러진 값들
"Keys": ["x", "y"],
"Condition": "and((x in [11, +inf)), (y in [1, +inf)))",
"Parts": 3/2,
"Granules": 10/6
}
]
테스트
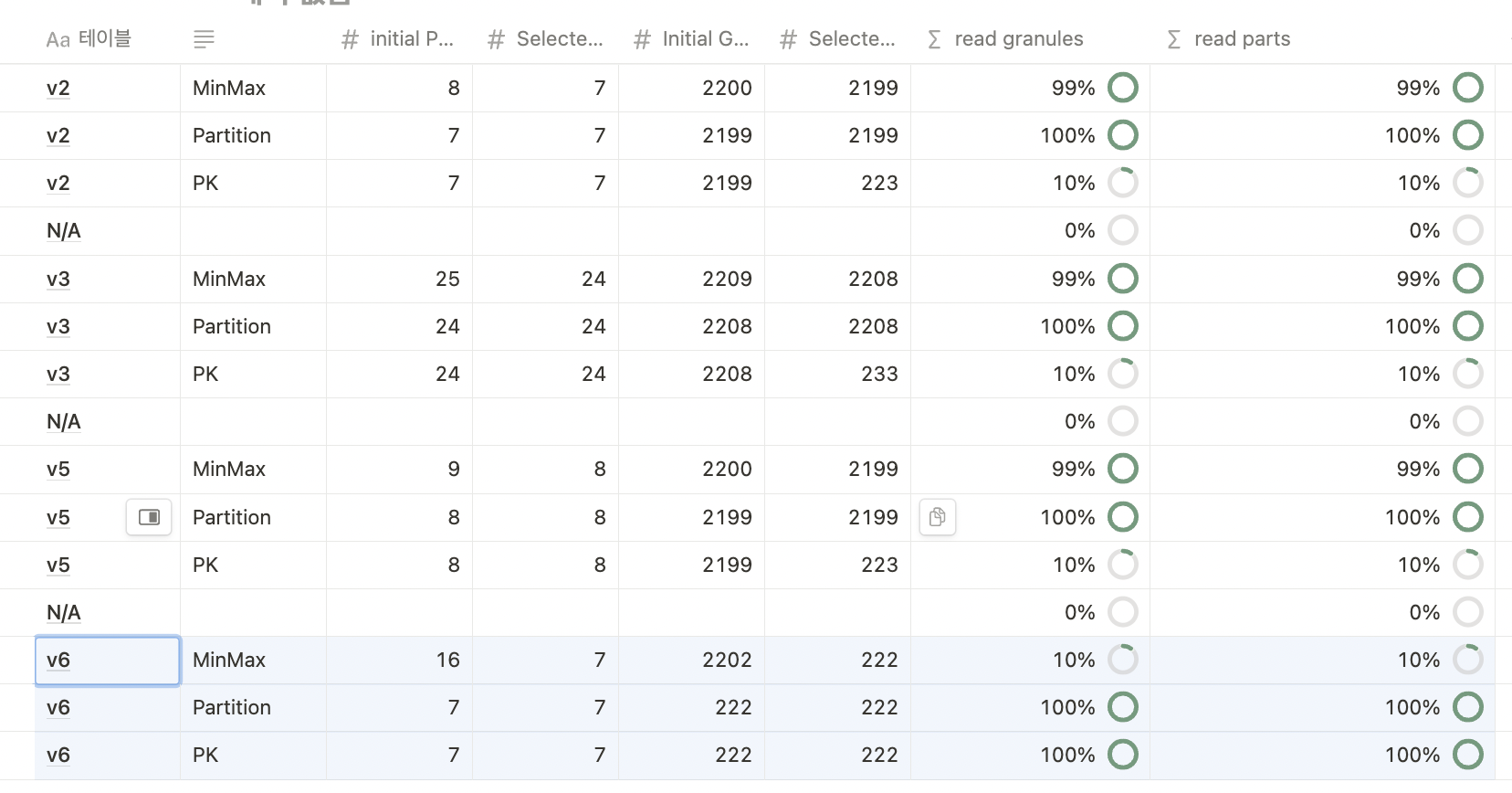
- 아래처럼 여러가지 ORDER BY 와 PARTITION BY 를 다양하게 적용했다.
- v2, v3, v5, v6
- 이중 처음 에 선택된 granules 가 가장 적은 것은 V6 이다 이것이 제일 좋은 파티션이라고 생각하면 되겠다.
728x90
반응형
'DataBase > Clickhouse' 카테고리의 다른 글
| [ClickHouse] 클릭하우스 Memory exceeded (0) | 2024.01.20 |
|---|---|
| [ClickHouse] 클릭하우스 클러스터 구축 (0) | 2023.05.27 |
| [ClickHouse] 클릭하우스 MergeTree 테이블 엔진 (0) | 2023.03.25 |
| [ClickHouse] 클릭하우스 란? (0) | 2023.03.18 |


댓글